Open Design:Claude Design 的开源平替代,让任何 AI 模型都能为你设计
引言:11天,一场开源对商业的惊艳“逆袭”
2026年4月,Anthropic 推出了 Claude Design,让 AI 能够直接产出精美的设计稿,迅速在开发者社群中引发了轰动。然而,它的封闭源代码、仅限云端付费使用的模式,也让许多人望而却步。
短短11天后,一位名为Tom Huang的开发者便向世界展示了开源的力量。他与其团队耗時72小时、编写超过18,700行代码,成功逆向工程推出了 Open Design(曾用名 Open Claude Design),在 X 平台上24小时内就获得了超过38万次观看与1600多个赞。项目上线后迅速在 GitHub 上累积了超过5000颗星,并持续增长。
这不仅是“复刻”,更是一次超越。Open Design 不仅重现了 Claude Design 超过95%的核心体验,更遵循“本地优先、开源可部署”的理念,把设计主权交还给了用户。
一、 什么是 Open Design?
Open Design 是一个“AI 设计工作流编排器”。
它不是一个简单的“文生图”工具,也不是一个封闭的 SaaS 产品。其核心价值在于:你不必再被特定的 AI 模型或平台绑定。Open Design 本身不内置“设计师”,而是利用你电脑上已有的编程 Agent(如 Claude Code, Cursor, Gemini CLI 等)作为设计引擎。
简单来说,它做了一个非常聪明的转换:把你手头只会写代码的 Agent,瞬间变成一个遵循严格设计规范、拥有海量品牌风格的高级设计师。
核心架构:Skills × Design Systems
Open Design 的强大源于其巧妙的架构设计,即“技能”与“设计系统”的笛卡尔积效应。
- 19个核心技能:它将设计任务模块化,内置了网页原型、PPT演示、仪表盘、营销邮件等19种具体的设计技能。每个技能都是一个包含详细指令和参考资料的文件夹。
- 71+套品牌设计系统:这是 Open Design 的杀手锏之一。它内置了包括 Stripe、Linear、Vercel、Apple、Notion、Spotify 等在内的71+套知名品牌的设计规范,涵盖色彩、字体、间距、组件等所有细节。
二、 为什么选择 Open Design?(对比 Claude Design)
为了让你更直观地了解它的优势,这里将它与原版的 Claude Design 进行一次详细对比:
| 对比维度 | Open Design (开源版) | Claude Design (官方版) |
|---|---|---|
| 开源协议 | ✅ Apache 2.0 开源 | ❌ 闭源商业产品 |
| 模型兼容 | ✅ 16种 CLI + BYOK API(可用任何模型) | ❌ 仅限 Anthropic 模型 |
| 部署方式 | ✅ 本地 / Vercel / Docker / 桌面App | ❌ 仅限云端 |
| 数据隐私 | ✅ 本地 SQLite 存储,数据完全自主 | ❌ 数据存储在云端 |
| 设计系统 | ✅ 71+套可切换,且可自行扩展 | ⚠️ 固定且不公开 |
| 费用 | ✅ 完全免费(自带 API Key 或 CLI) | ❌ 最低 $20/月起 |
| 核心机制 | ✅ 反AI-slop,通过问卷和自检确保质量 | ⚠️ 较为依赖模型本身 |
关键优势: Open Design 内置了一套 “反AI-slop”机制,防止 AI 生成那些千篇一律的“廉价设计”(例如泛滥的紫色渐变、圆角卡片配侧边色块等)。它通过前置问卷、品牌色提取协议和五维自我批判机制,强迫 AI 按专业设计师的工作流产出内容,从而显著提升质量。
三、 快速上手:3步完成本地部署
只要你的电脑上准备好了必要的工具,整个安装过程不会超过10分钟。
1. 环境准备
在开始之前,请确认你的电脑已经安装了以下工具:
| 依赖项 | 版本要求 | 检查命令 | 安装 | 说明 |
|---|---|---|---|---|
| Node.js | v20 或更高 | node -v |
推荐使用 nvm 管理版本 | |
| pnpm | 10.33.x 或更高 | pnpm -v |
brew install corepack |
通过 corepack enable 启用 |
| Git | 任意版本 | git --version |
用于克隆仓库 | |
| AI CLI(可选,但推荐) | 任一即可 | which claude |
Claude Code / Codex / Cursor 等 |
2. 安装和配置
打开你的终端(Terminal),一次执行以下命令:
第一步:安装项目
1 | # 克隆项目 |
第二步:配置 API(关键步骤)
Open Design 支持两种模式,你可以根据自己的情况选择:
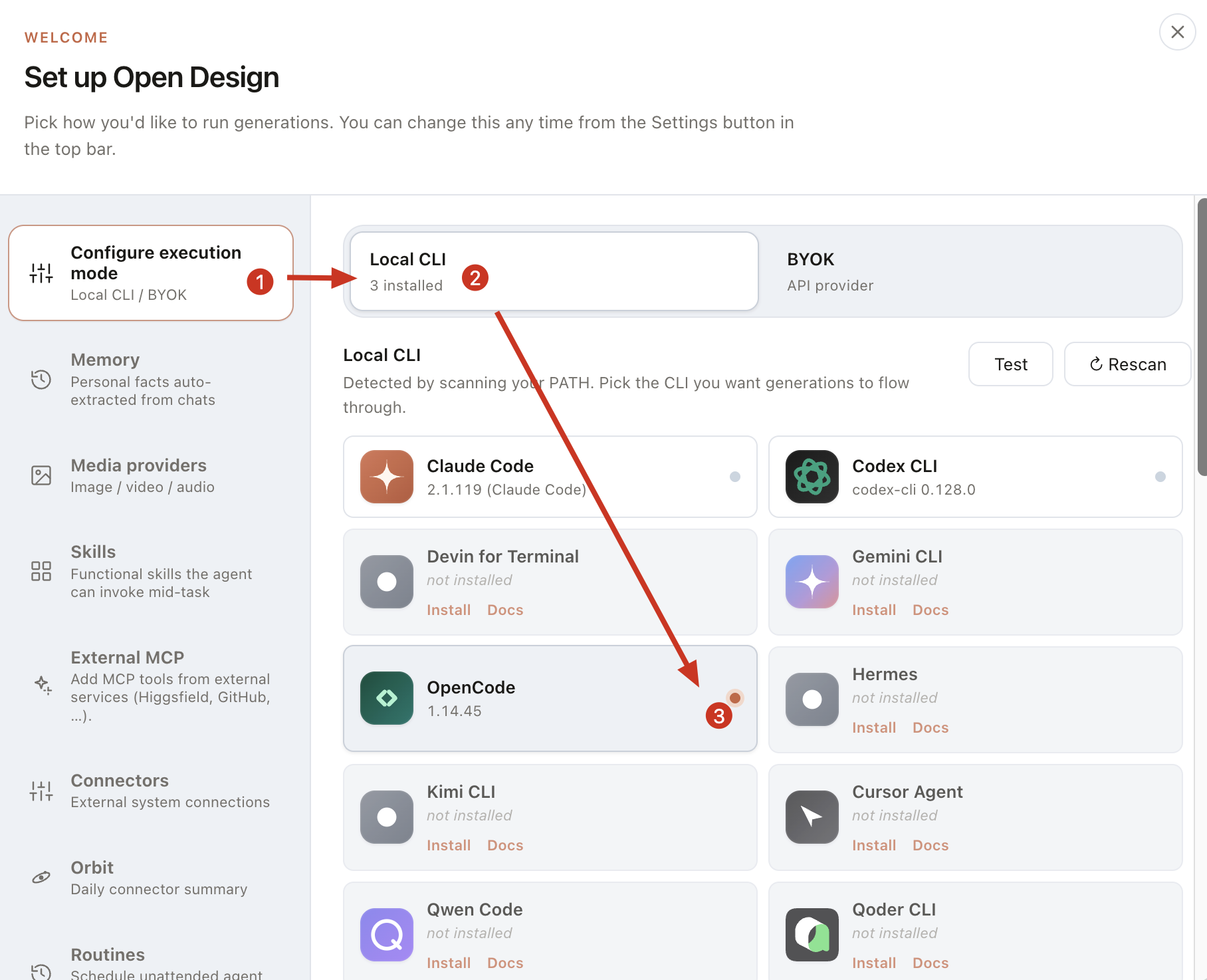
方式一:CLI 模式
如果你已经安装了 Claude Code 等 CLI 工具,Open Design 会自动扫描并优先使用它们,无需额外配置。
方式二:BYOK 模式(推荐国内用户)
如果没安装,你需要自己配置。此方式也适合你用国内模型来配置。
1 | # macOS / Linux |
之后如果要修改配置也可以在启动服务里修改:
3、启动
配置完成后,运行如下命令即可生效。
1 | pnpm tools-dev run web |
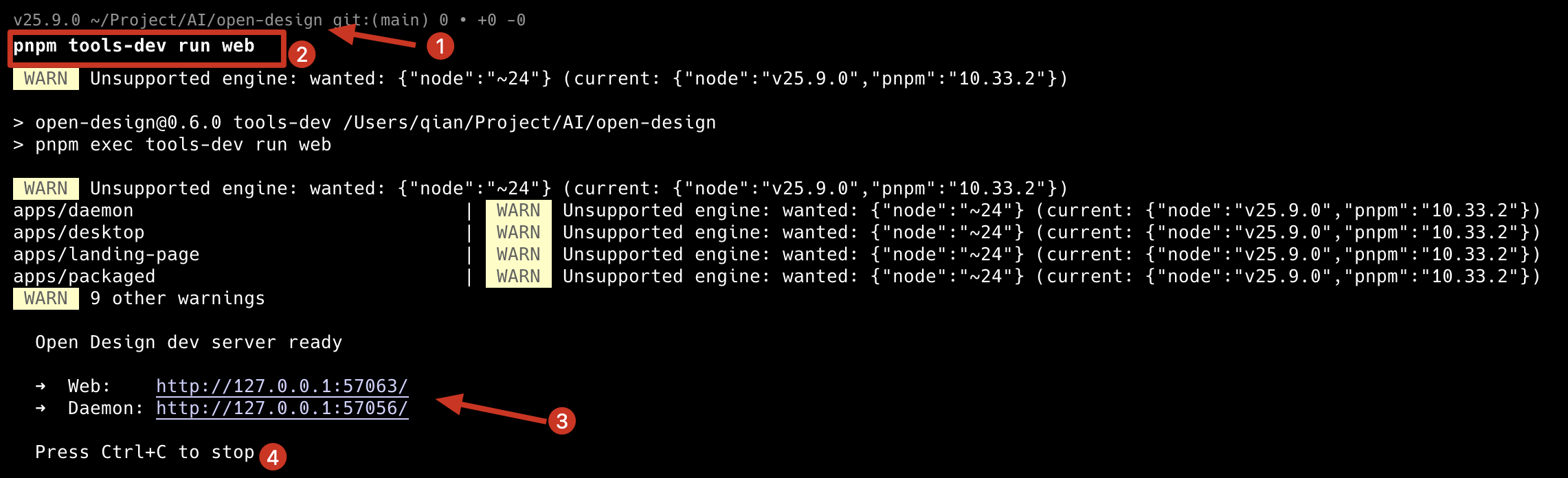
启动成功后,在浏览器中打开给出的Web地址,即可。
如果要关闭关闭服务
1 | # 在终端窗口中,按下: |
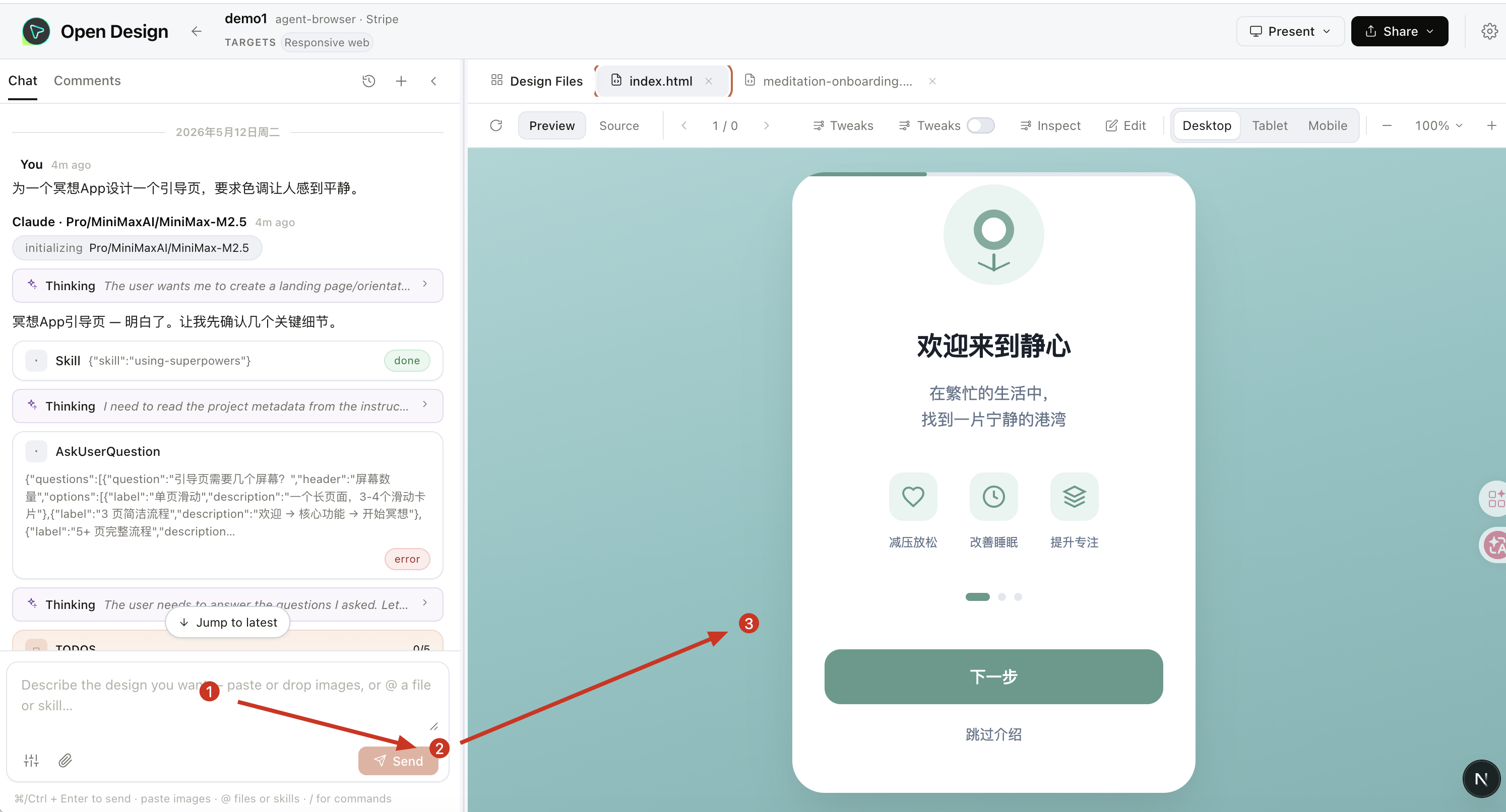
四、 在浏览器中的使用示例:让你的第一个设计诞生
打开浏览器,访问给出的web地址
http://127.0.0.1:57063/。在左侧选择一个 Skill(建议新手从
web-prototype开始)。在右侧选择一个 Design System(试试
stripe或linear,感受一下顶级品牌的视觉风格)。在中央的输入框中,用自然语言描述你的需求,例如:
“为一个冥想App设计一个引导页,要求色调让人感到平静。”
点击生成。你会先看到一个需求表单,这是 Open Design 的关键一步,它会引导你明确“为谁设计”、“什么风格”、“尺寸如何”等细节。
填写完表单,点击确认,然后你就可以在时间线上看到 Agent 的实时计划进度,并最终获得一个可直接运行的 HTML 网页或设计稿。
初始安装/opencode_ses_1exit.png)
初始安装/opencode_ses_2continue.png)