自己的文章:
一、Jenkins的安装
①、直接下载Jenkins安装。
1 | brew install jenkins-lts |
②、安装成功后,其会自动打开http://localhost:8080
此时如果我们发现打开错误。原因是我们缺少Jenkins的运行环境,所以我们需要安装java的jdk。如果要验证是否是这个原因的话,我们可以通过命令行查看当前的java版本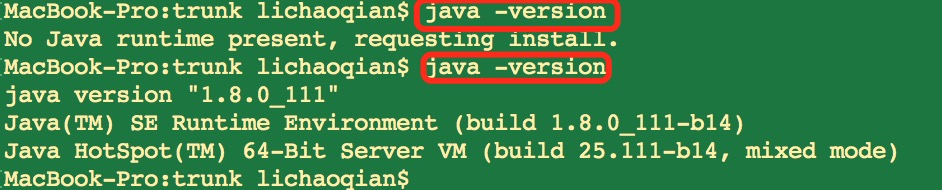
果然发现没有安装,则我们通过下载jdk来进行安装。
java的jdk下载地址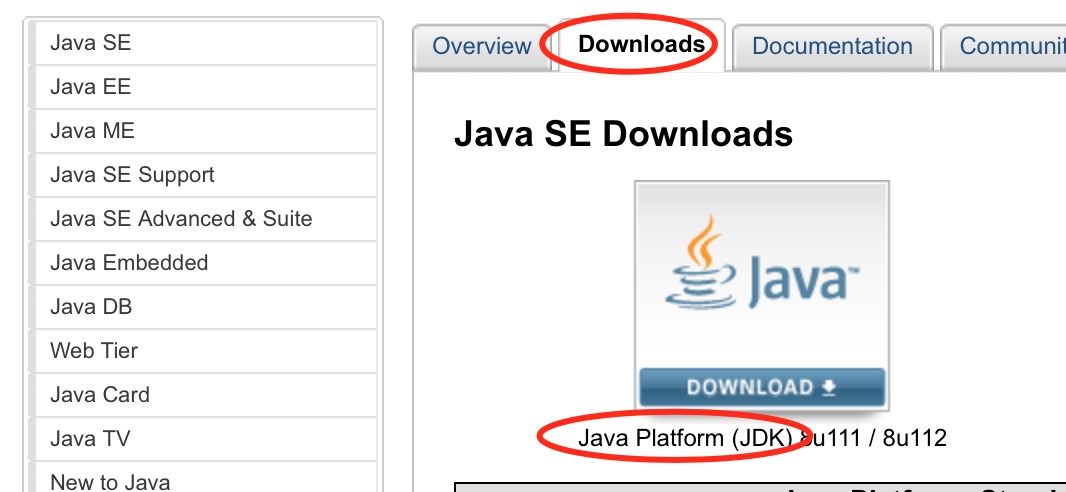
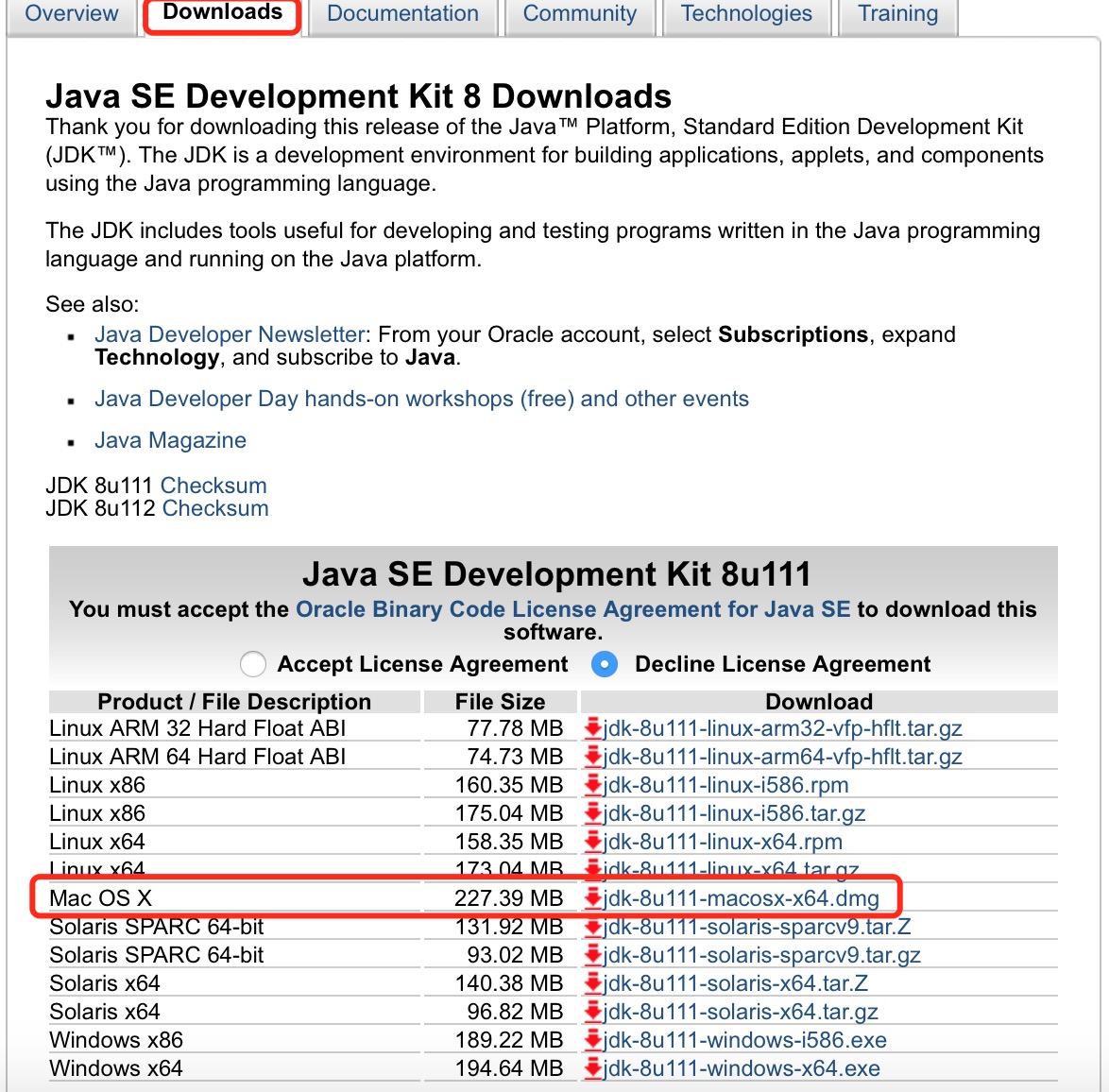
安装完后,我们再运行一下验证命令,发现可以运行了,即我们安装好了。
③、java环境安装成功之后,接下来我们就可以正常访问Jenkins了。Jenkins的访问地址为http://localhost:8080。打开的页面显示如下: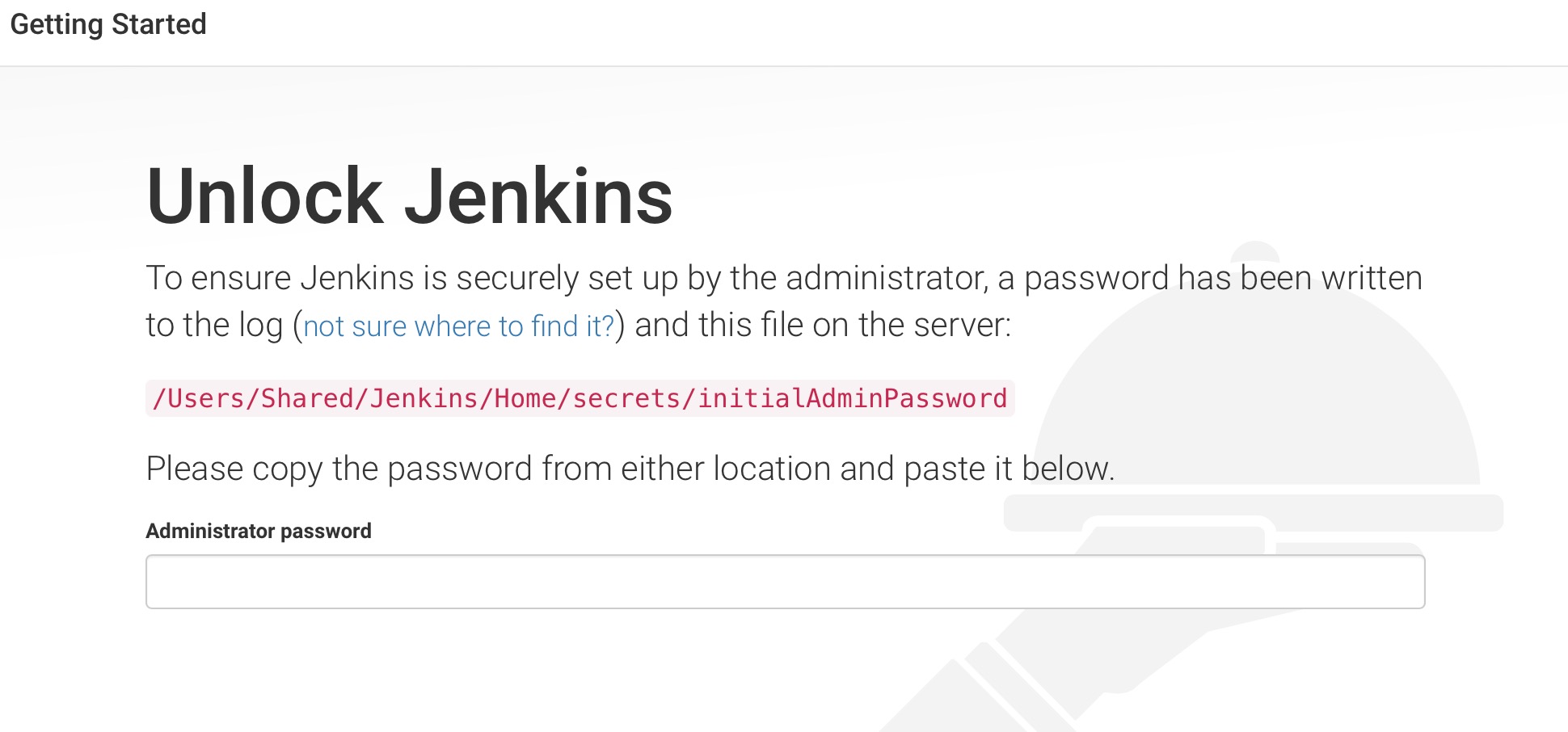
④、提示我们需要输入其指定文件夹下的密码来访问。则我们访问其指定文件,发现没法访问该文件内容
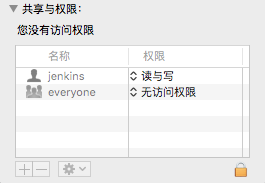
所以这里我们通过修改权限,让读取该文件内容,如下: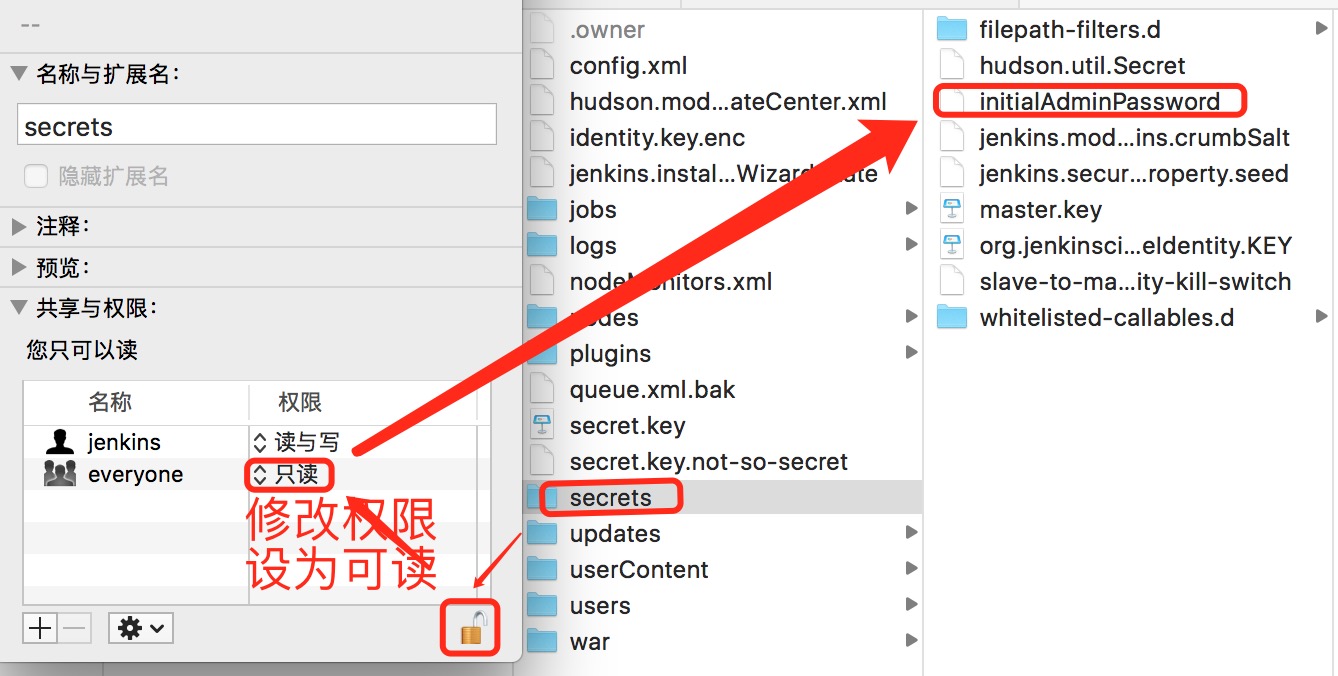
⑤、将读取后的密码输入到登录网页上,即可登录,登录后的结果为: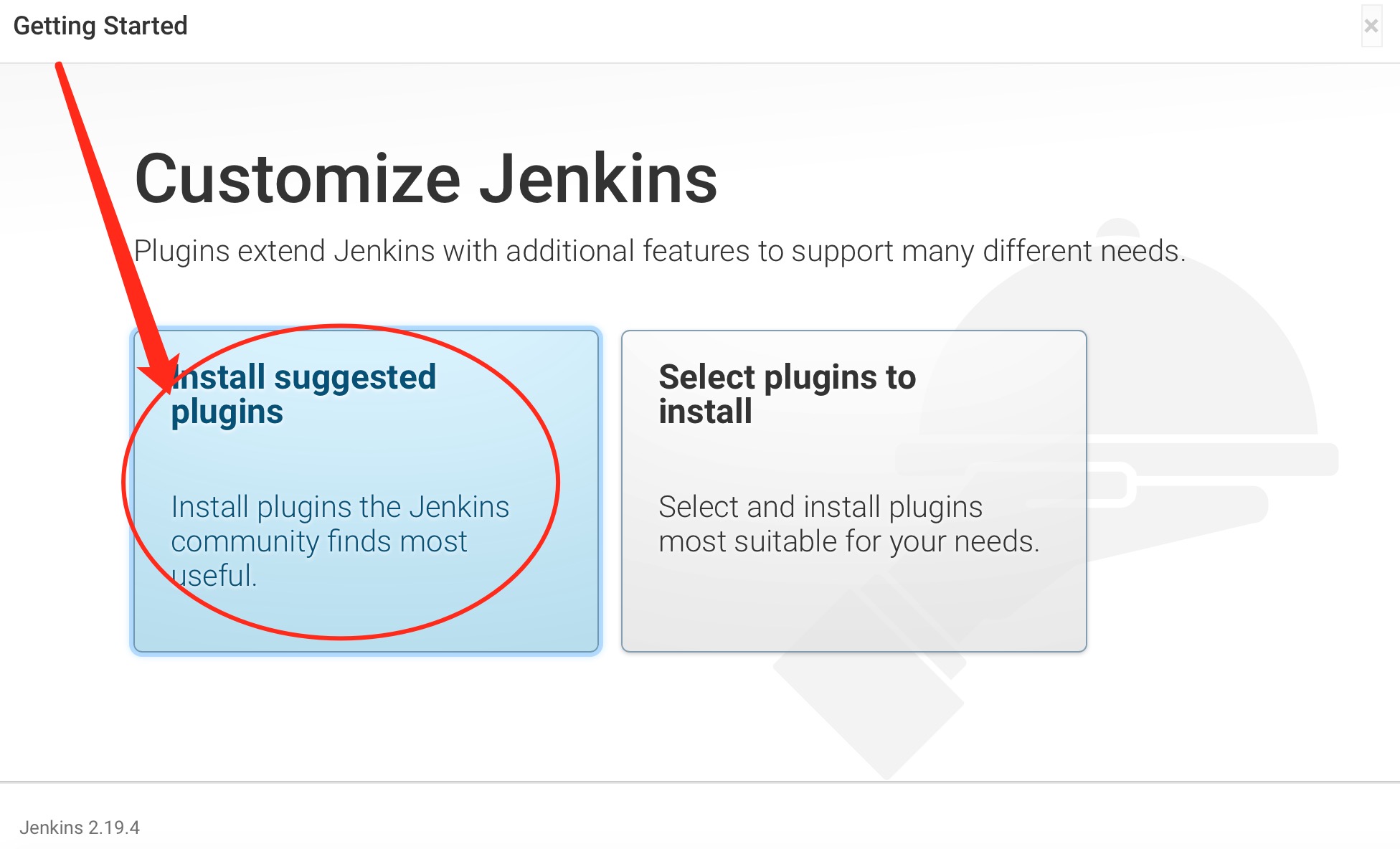
⑥、因为此时为首次登陆,所以其会提示我们安装Jenkins建议的插件。则我们按照步骤进行Jenkins默认插件的安装。安装过程如下所示: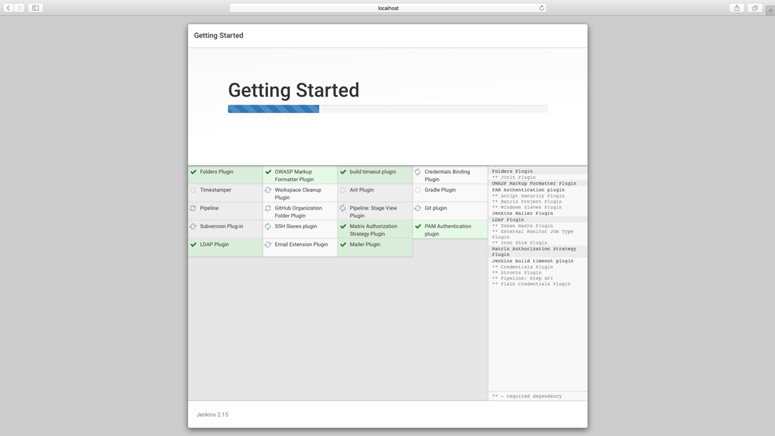
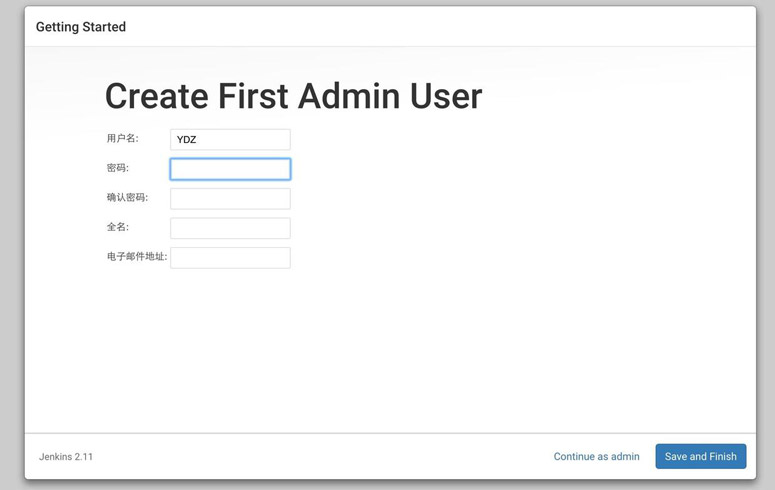
⑦、一路安装过来,输入用户名,密码。
之后继续登录http://localhost:8080/可以看到最终的显示结果为: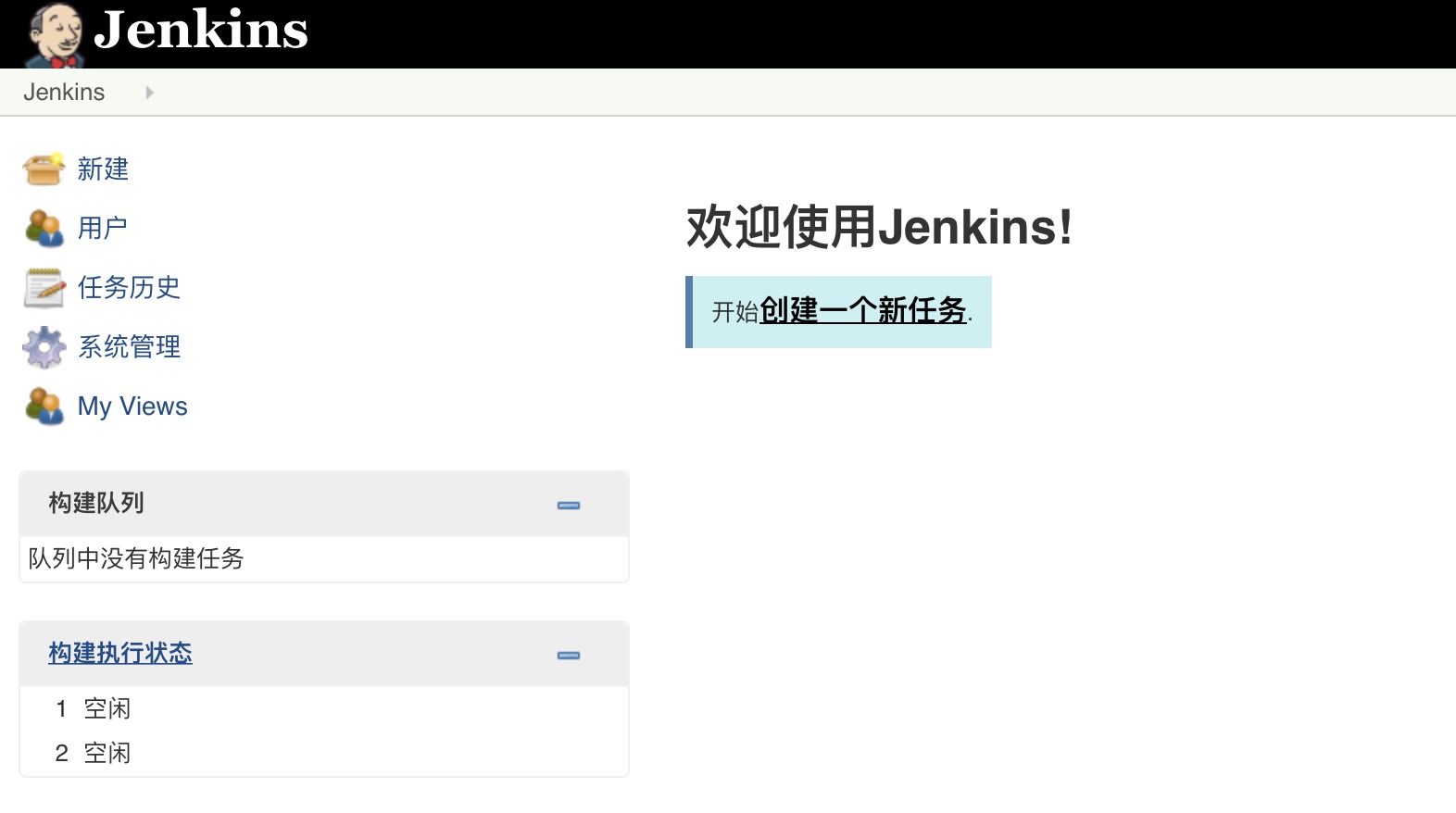
此时则我们的Jenkins的初始安装完毕(之后我们可能还需要安装一些自己需要的插件)。
二、Jenkins的启动
没有权限问题的Jenkins正确的启动方式如下(按下面方式打开,才不会出现权限问题):
1 | sudo launchctl unload /Library/LaunchDaemons/org.jenkins-ci.plist |
当你执行完这两行命令的时候,你可以在浏览器上输入http://localhost:8080来访问Jenkins了。(如果你只执行了第一行,没执行第二行,会出现无法访问)
三、Jenkins的升级
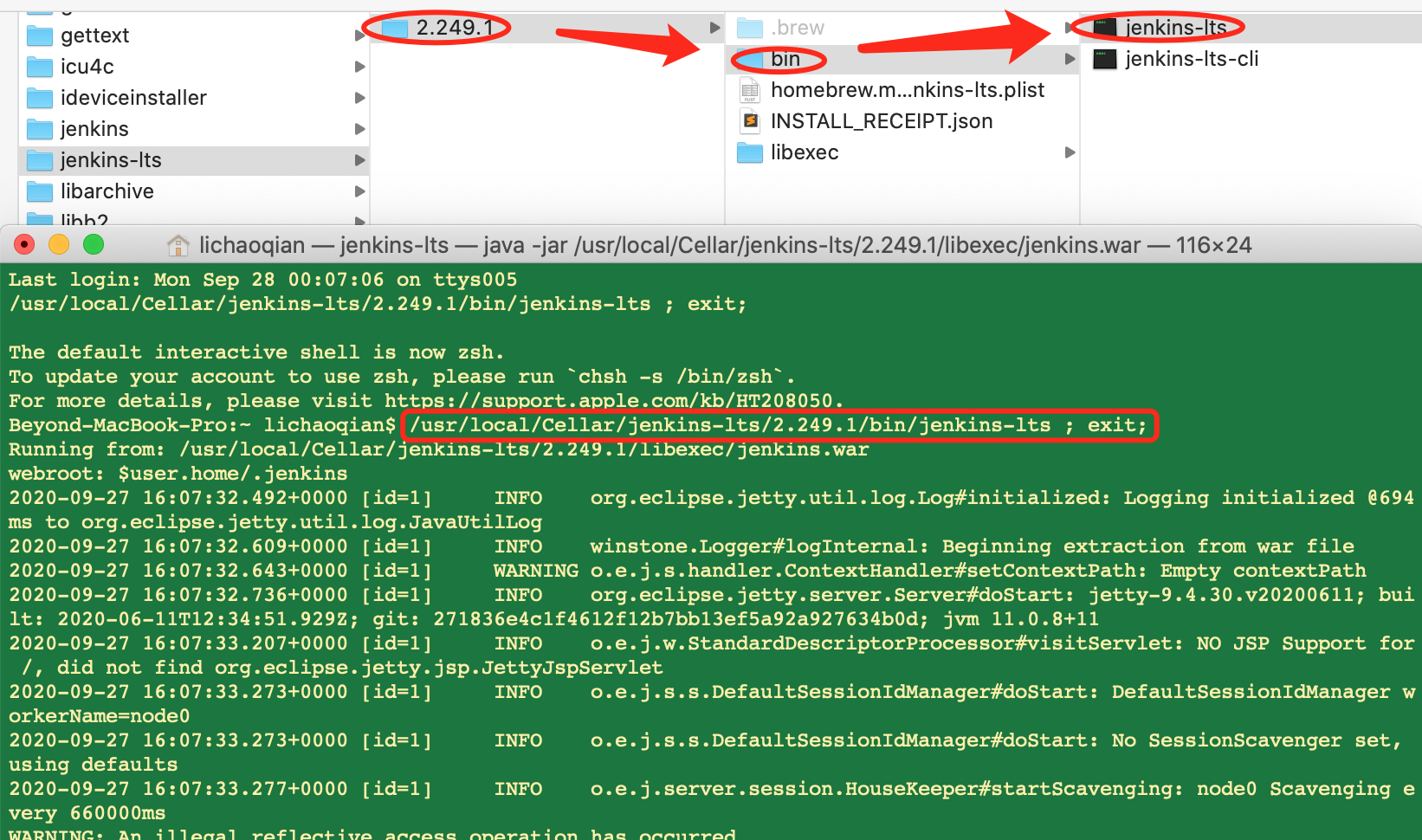
1、如何查看jenkins 的版本号
jenkins页面的右下角就是jenkins版本号信息
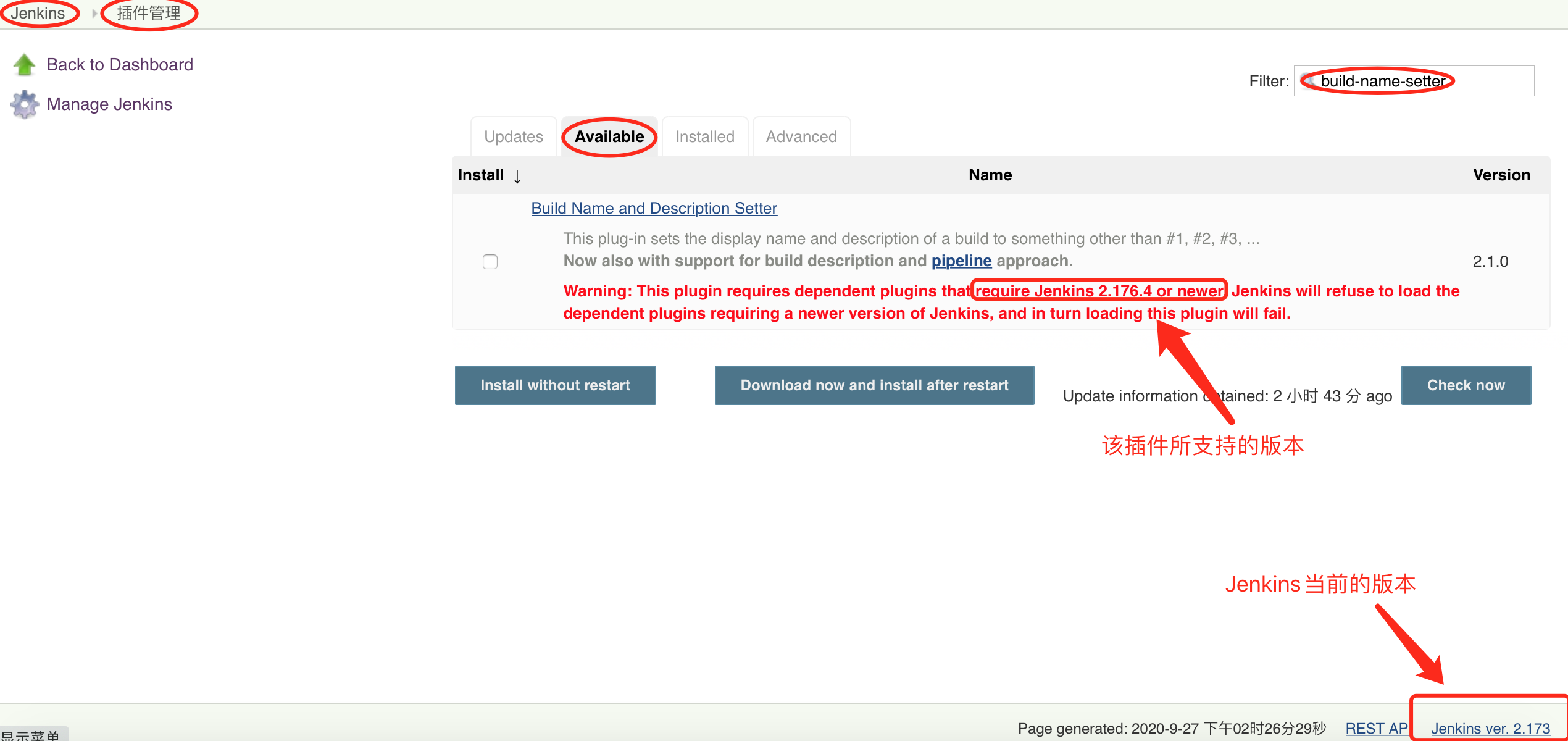
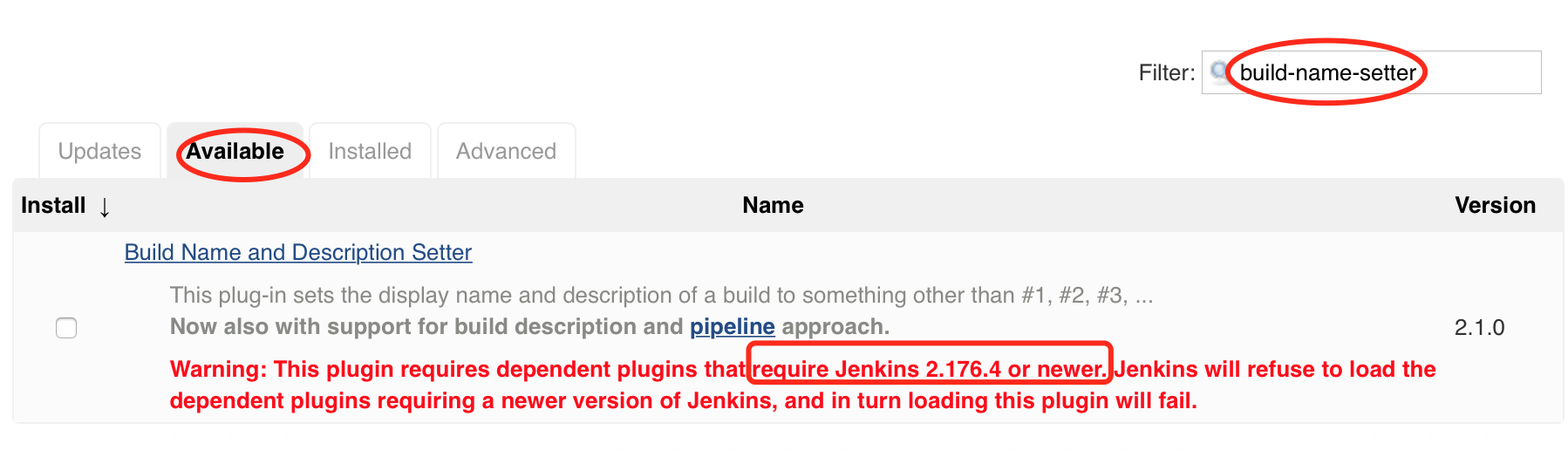
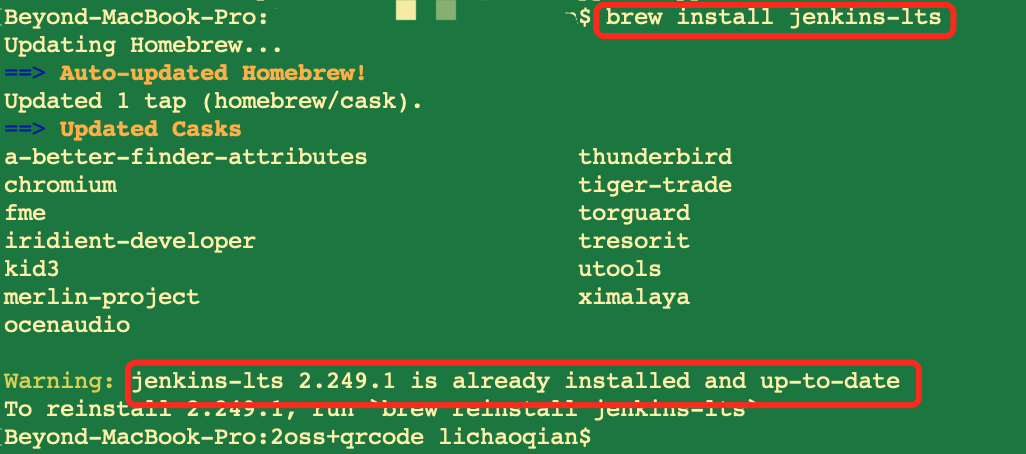
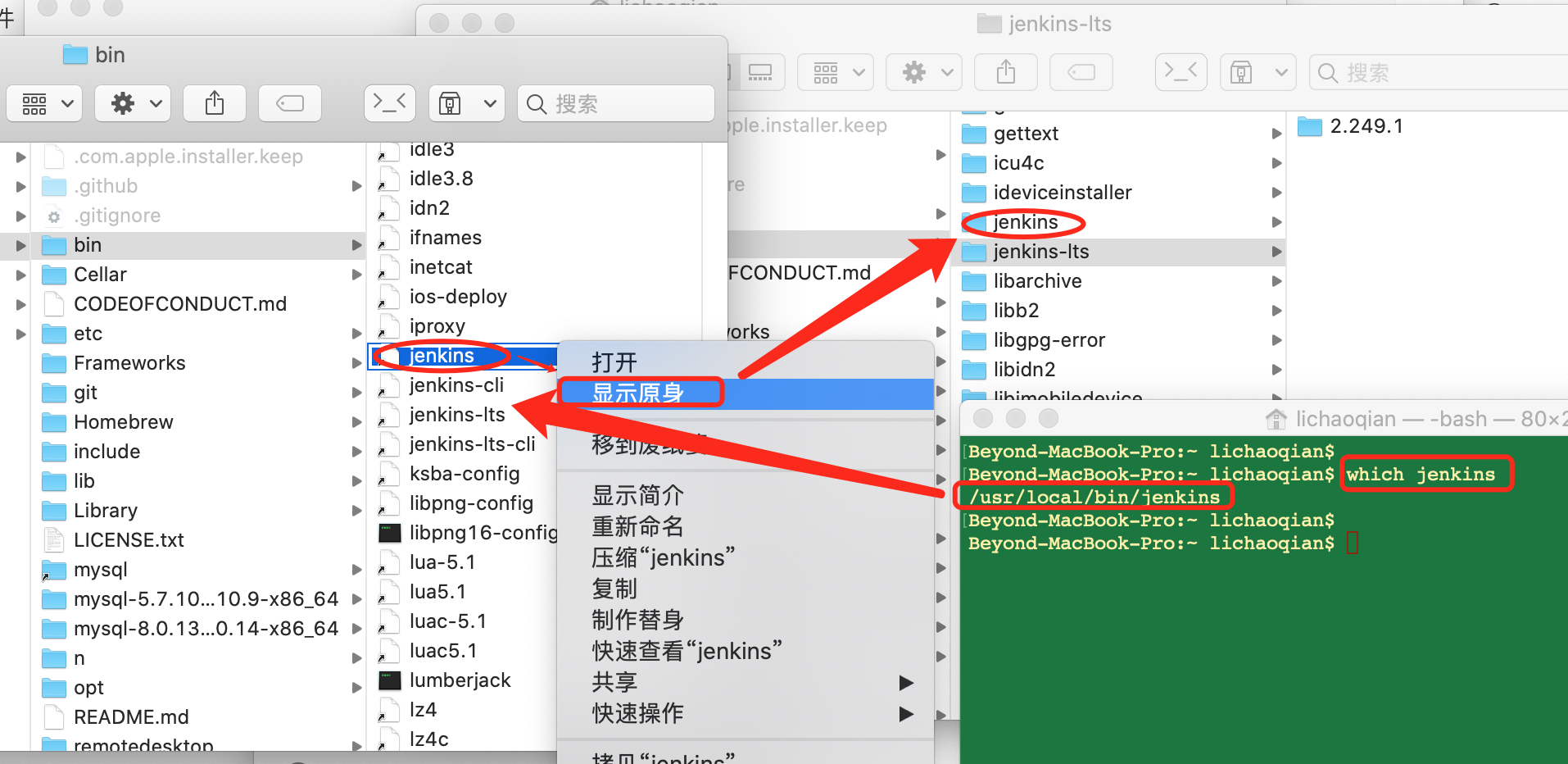
要执行下载好的版本