第一步:创建一个 Telegram 机器人
1.1 打开 BotFather
在 Telegram 中搜索@BotFather(官方机器人管理器),然后开始聊天。
⚠️ Make sure it’s the verified official BotFather — don’t use third-party imitations.
⚠️ 请确保使用的是经过验证的官方 BotFather 账号——切勿使用第三方仿冒账号。
1.2 创建新机器人
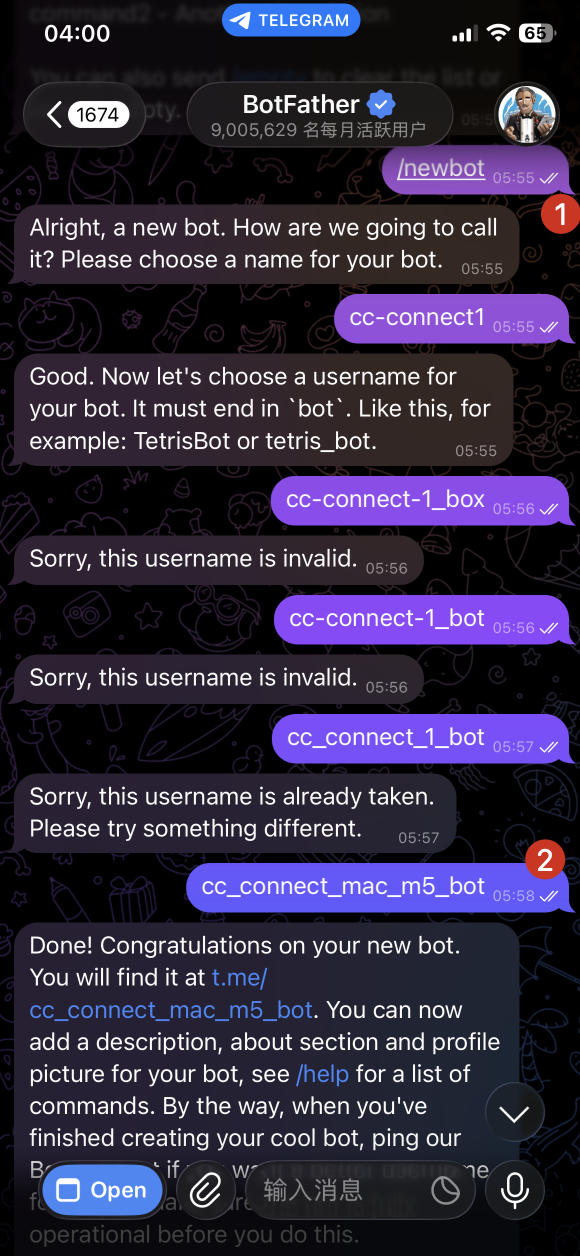
发送命令 /newbot 。BotFather 会要求你输入名称和用户名。
1.3 Set the Bot Name 1.3 设置机器人名称
请输入你的机器人的显示名称(例如: cc-connect )。
1.4 Set the Bot Username 1.4 设置机器人的用户名
请输入用户名(用户名必须以 bot 结尾,例如 cc_connect_bot )。
💡 Naming rules: 💡 命名规则:
- Must end with
bot(case-insensitive)
必须以bot结尾(不区分大小写)- Only letters, numbers, and underscores
只能包含字母、数字和下划线。- Must be globally unique
必须具有全球唯一性
1.5 Get the Bot Token 1.5 获取机器人令牌
After creation, BotFather will reply with something like:
创建完成后,BotFather 会回复类似这样的内容:
1 | Done! Congratulations on your new bot... |
⚠️ Save this token immediately — it’s only shown once! If lost, use
/mybots→ select bot →API Token→Revoke current tokento regenerate.
⚠️ 请立即保存此令牌——它只会显示一次而已!如果丢失了,请使用/mybots→ 选择机器人 →API Token→Revoke current token来重新生成。
得到 HTTP API
二、获取 个人聊天 ID 或者 群聊 ID
1、借助三方机器人 @get_id_bot
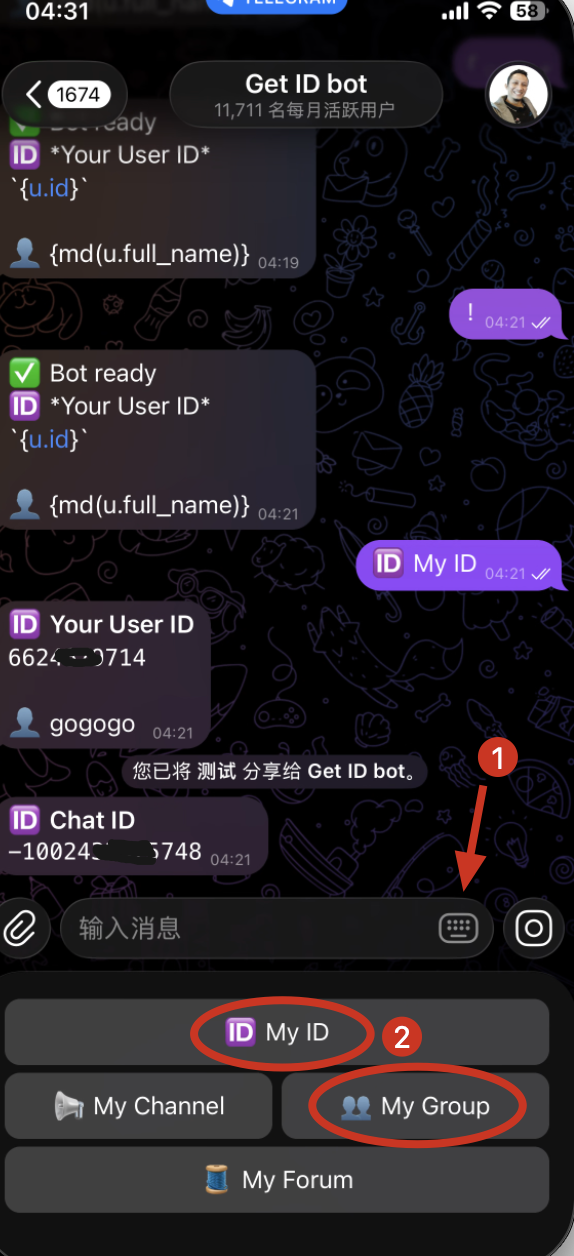
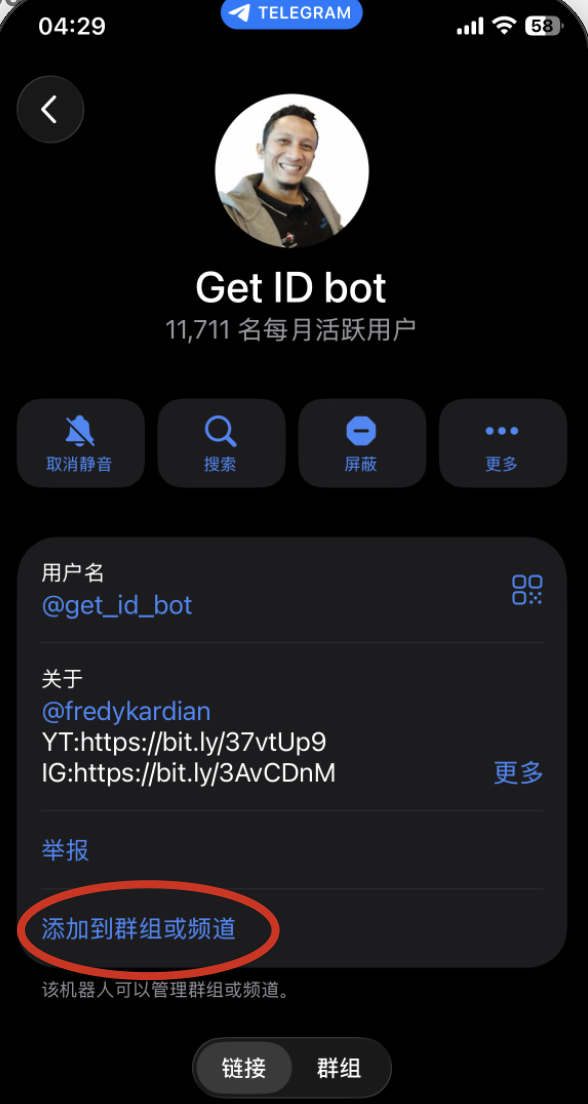
搜索 @get_id_bot 机器人,然后也有两种使用方式
方式一:进入与其私聊界面,选择标记1,弹出如下指示面板(注意不是发消息,而是选择面板里的选项)。
选择 My ID 即为个人聊天 ID;
选择 My Group ,则在分享后获得群聊 ID。
方式二:通过 ”添加到群组或者频道“ ,将其添加到你的群组里
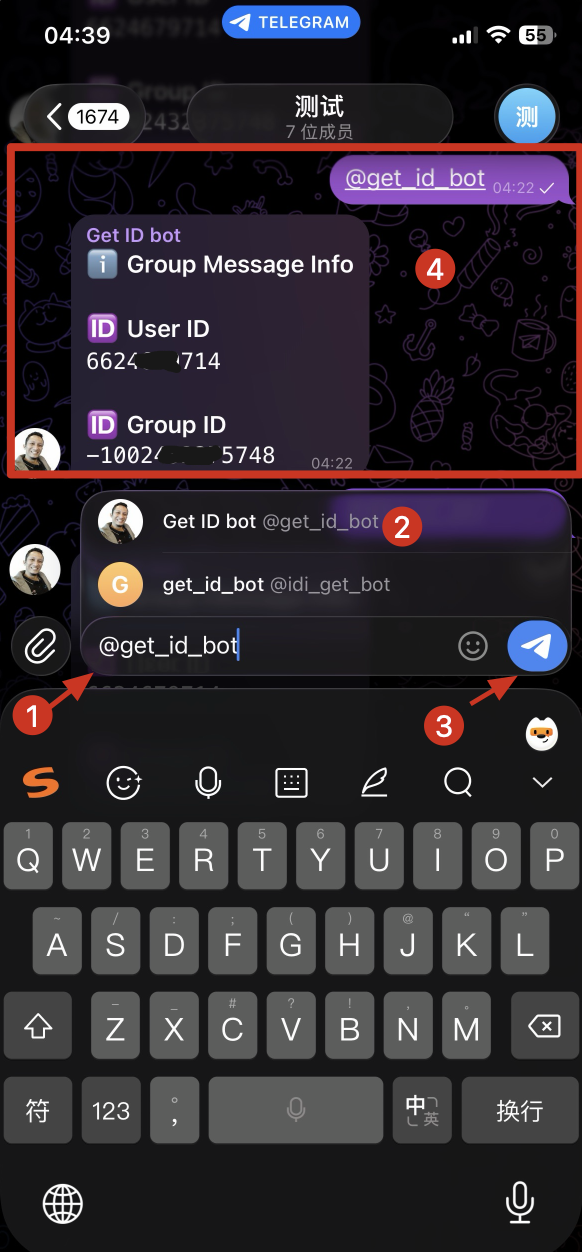
2、不借助三方机器人,纯靠自己的机器人 token
2.1 获取您的个人聊天 ID
将以下地址的
{{TOKEN}}替换为您的机器人的Token,换完后访问以下网址:1
https://api.telegram.org/bot{{TOKEN}}/getUpdates
如果复制粘贴到浏览器地址栏,没发消息就回车请求。不出意外你会得到如下 response
1
2
3
4{
"ok": true,
"result": []
}所以我们要向你的机器人发送任何消息。然后刷新网址,得到类似如下的结果
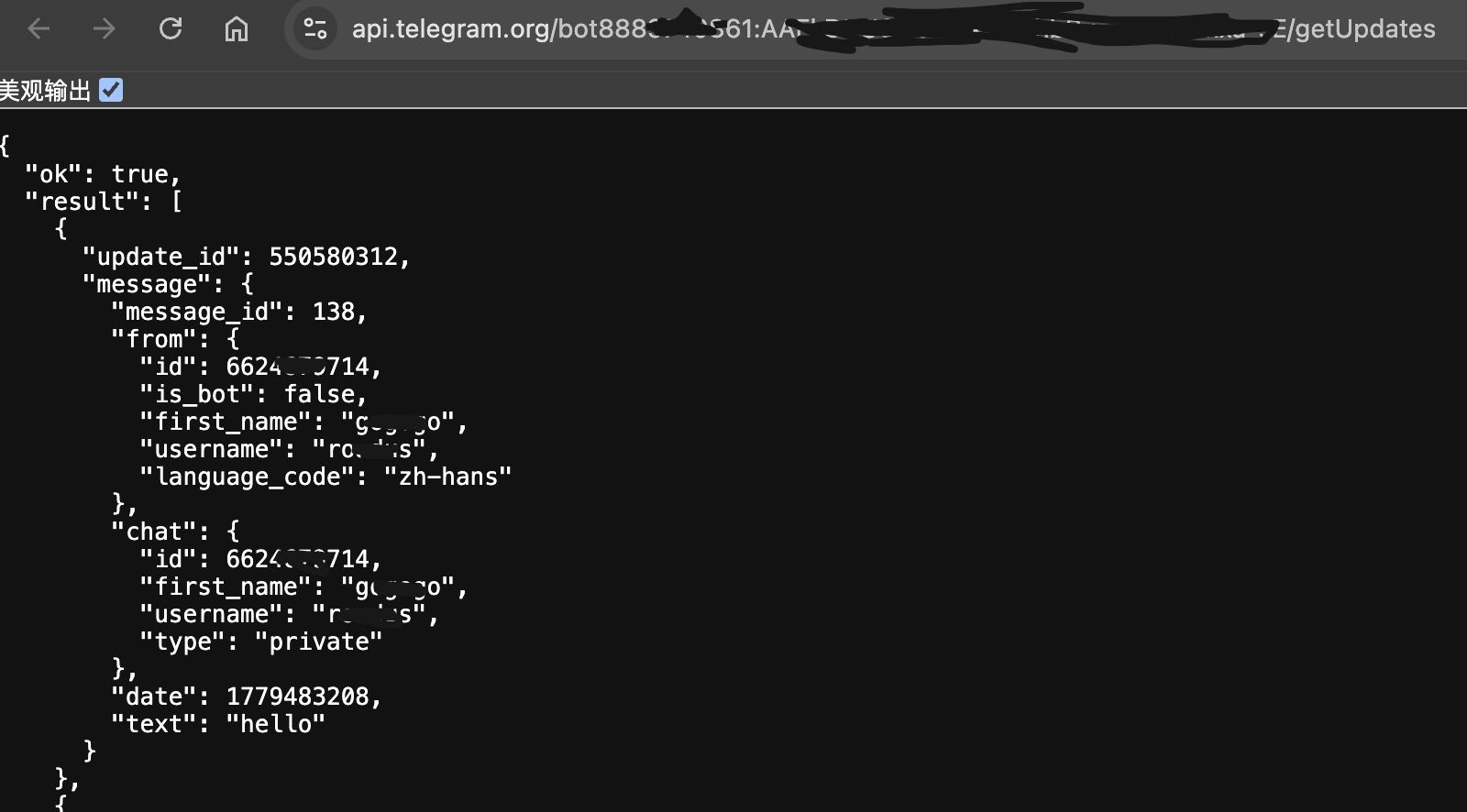
在返回的 JSON 数据中找到
chat.id字段,即为你的用户id。
2.2 获取群聊 ID
- 将该机器人添加到某个群组中。
- 在群组中发送消息时,请务必提及@your_bot。
- 请查看
getUpdates网址——群组聊天 ID 通常为负数。
三、设置机器人指令(可选)
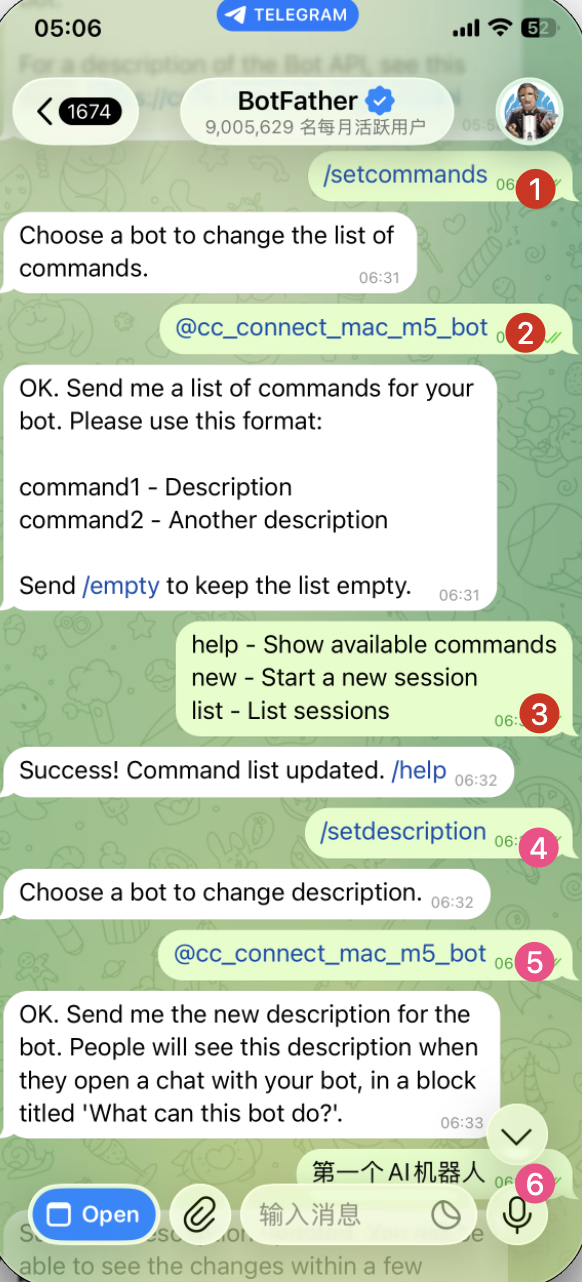
1. Set Command Menu 设置命令菜单
在 BotFather 中发送:
1 | /setcommands |
请选择您的机器人,然后输入命令列表:
1 | help - Show available commands |
2. Set Bot Description 设置机器人描述
1 | /setdescription |
请输入描述内容——用户首次使用该机器人时就会看到这些文字。
四、重置Token
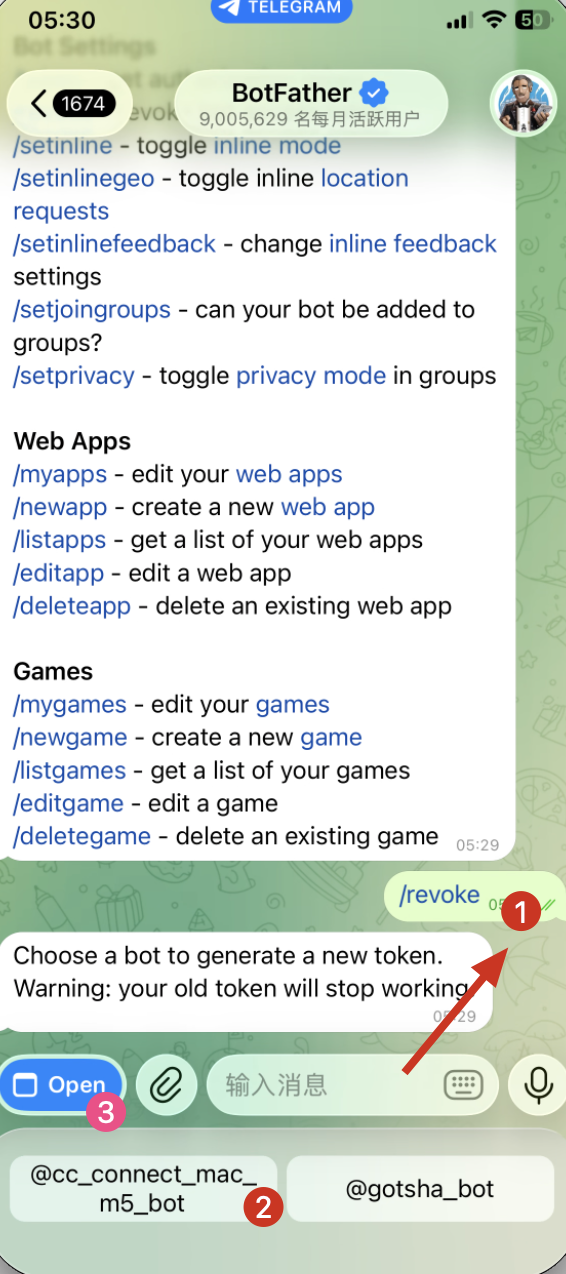
方式1:输入命令(如图中①②)
- 进入 BotFather 聊天界面,输入/revoke
- 请选择你的机器人。
方式2:选择小程序(如图中③)