一般的合併方式,有些情況(非快轉合併)會產生一個額外的 commit 來接合兩邊分支,而 rebase 合併分支跟一般的合併分支的明顯差別,就是使用 rebase 方式合併分支不會有這個合併的 Commit。
如果就以最後的的結果來說,檔案內容來說是沒什麼差別,但在 Git 的歷史紀錄上來說就有一些差別,誰 rebase 誰,會造成歷史紀錄上先後順序不同的差別。例如 cat 分支 rebase 到 dog 分支的話,表示 cat 分支會被接到 dog 分支的後面;反之如果是 dog 分支 rebase 到 cat 上的話,表示 dog分支 會被接到 cat 分支的後面。
使用 rebase 的好處,是整理出來的歷史紀錄不會有合併用的 commit,看起來比較乾淨(也是有些人不覺得這乾淨多少),另外歷史紀錄的順序可以依照誰 rebase 誰而決定先後關係(不過這點不一定是優點或缺點,端看整理的人而定);缺點就是它相對的比一般的合併來得沒那麼直覺,一個不小心可能會弄壞掉而且還不知道怎麼 reset 回來,或是發生衝突的時候就會停在一半,對不熟悉 rebase 的人來說也許是個困擾。
通常在還沒有推出去但感覺得有點亂(或太瑣碎)的 commit,我會先使用 rebase 來整理分支後再推出去。rebase 等於是在修改歷史,這個行為會做出平行時空,修改已經推出去的歷史可能會對其它人帶來困擾,所以對於已經推出去的內容,請不要任意使用 rebase。
【狀況題】怎麼有時候推不上去…
偶爾在執行 Push 指令的時候會出現這個錯誤訊息:
1 2 3 4 5 6 7 8 9
$ git push To https://github.com/eddiekao/dummy-git.git ! [rejected] master -> master (fetch first) error: failed to push some refs to 'https://github.com/eddiekao/dummy-git.git' hint: Updates were rejected because the remote contains work that you do hint: not have locally. This is usually caused by another repository pushing hint: to the same ref. You may want to first integrate the remote changes hint: (e.g., 'git pull ...') before pushing again. hint: See the 'Note about fast-forwards' in 'git push --help' for details.
這段訊息的意思是線上版本的內容比你電腦裡這份還要新,所以 Git 不讓你推上去。
怎麼造成的?
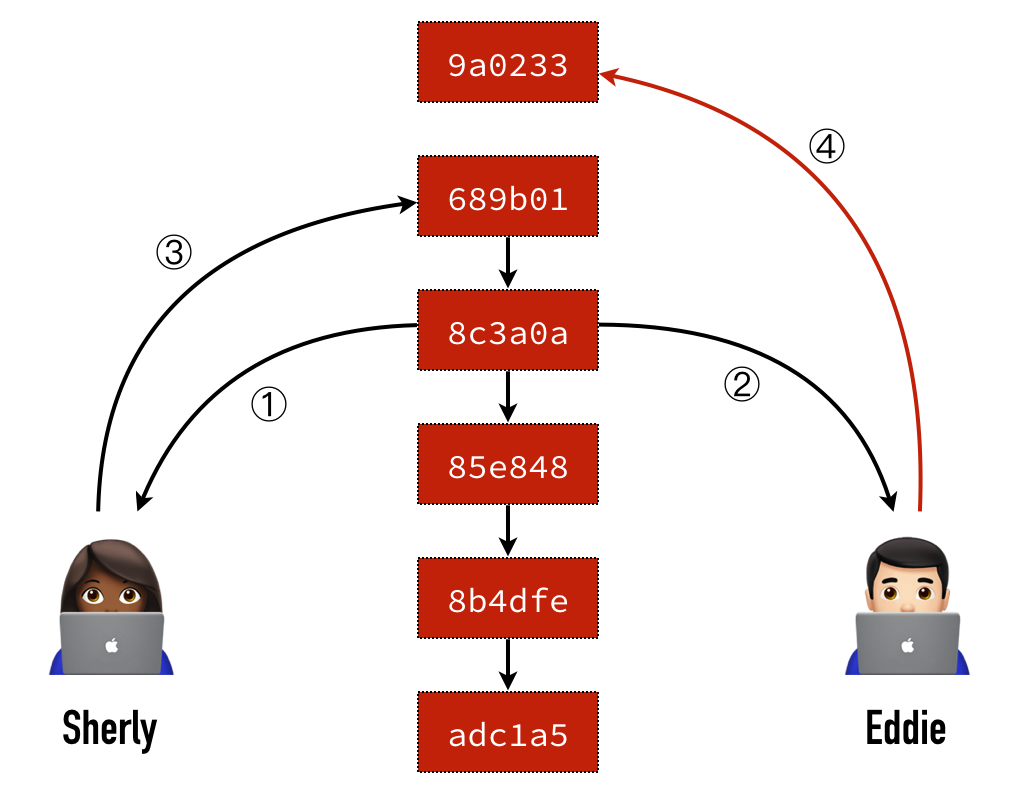
通常這個狀況會發生在多人一起開發的時候,想像一下這個情境:
Sherly 跟 Eddie 兩個人在差不多的時間都從 Git Server 上拉了一份資料下來準備進行開發。
Sherly 手腳比較快,先完成了,於是先把做好的成果推一份上去。
Eddie 不久後也完成了,但當他要推上去的時候發現推不上去了…
怎麼解決?
解決方法算是有兩招
第一招:先拉再推
因為你電腦裡的內容是比較舊的,所以你應該先拉一份線上版本的回來更新,然後再推一次:
1 2 3 4 5 6 7 8 9
$ git pull --rebase remote: Counting objects: 3, done. remote: Compressing objects: 100% (2/2), done. remote: Total 3 (delta 1), reused 3 (delta 1), pack-reused 0 Unpacking objects: 100% (3/3), done. From https://github.com/eddiekao/dummy-git 37aaef6..bab4d89 master -> origin/master First, rewinding head to replay your work on top of it... Applying: update index
這裡加了 --rebase 參數是表示「內容抓下來之後請使用 Rebase 方式合併」,當然你想用一般的合併方式也沒問題。合併如果沒發生衝突,接著應該就可以順利往上推了。
test() async { Completer c = new Completer(); for (var i = 0; i < 1000; i++) { if (i == 900 && c.isCompleted == false) { c.completeError('error in $i'); } if (i == 800 && c.isCompleted == false) { c.complete('complete in $i'); } }
try { String res = await c.future; print(res); //得到complete传入的返回值 'complete in 800' } catch (e) { print(e);//捕获completeError返回的错误 } }
怎么将一个Callback回调转化成Future同步方法(Callback to Future),可以配套async / await去使用呢?
Here are main question we will ask during interview: 1.Data Structure: a.linked lists b.Stacks c.Queues d.binary trees e.hash tables 2.Algorithms: a.Sort (like quick sort and merge sort), binary search, greedy algorithms. b.Binary tree(like traversal, construction, manipulation..) You can find more to do exercises on https://leetcode.com/