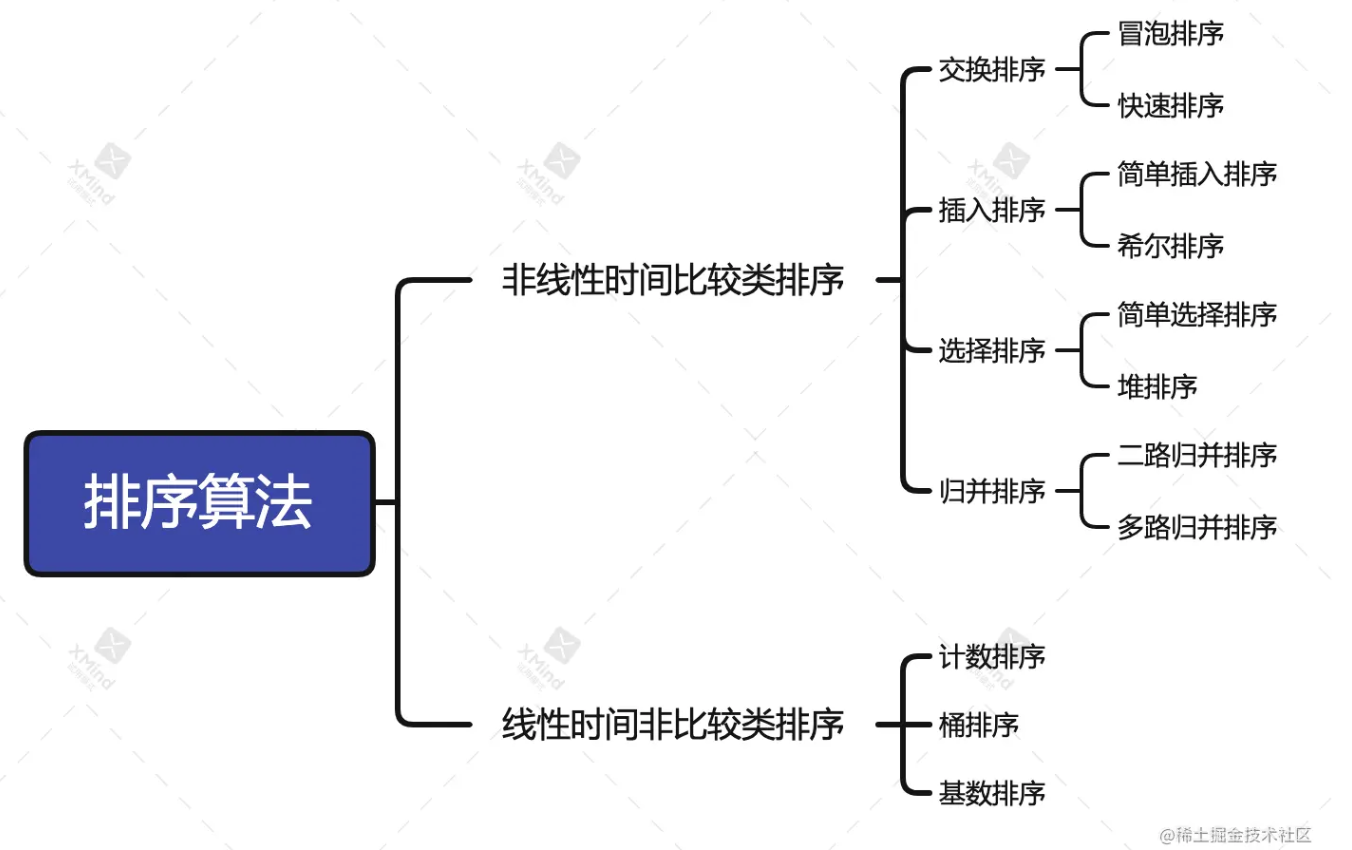
必备知识架构-算法
稳定与不稳定:如果a原本在b的前面并且a=b,排序之后a仍然在b的前面那就是稳定排序,如果排序之后a可能会出现在b的后面则是不稳定排序。所以冒泡排序是稳定的。选择排序可能不稳定。
空间复杂度:是指算法在计算机内执行时所需的存储空间与n的规模之间的关系。
时间复杂度:排序的的总操作次数,与n的规模之间的关系。
以下是我们在面试中要问的主要问题:
1.数据结构:
a、 链表
b、 堆叠
c、 排队
d、 二叉树
e、 哈希表
2.算法:
a、 排序(像快速排序和归并排序),二分搜索法,贪婪算法。
b、 二叉树(比如遍历、构造、操作…)
iOS 开发中常用的排序(冒泡、选择、快速、插入、希尔、归并、基数)算法
| 排序算法 | 平均时间复杂度 | 其他时间复杂度 | 平均空间复杂度 | 是否是稳定性的 |
|---|---|---|---|---|
| 冒泡排序 | O(n^2) | 最好:O(n),已是有序的 最坏:O(n^2),是逆序的 |
O(1) | 稳定 |
| 选择排序 | O(n^2) | —— | O(1) | 不稳定 |
| 快速排序 | O(nlogn) | 最好:O(nlogn),每次划分都非常平衡时 最坏:O(n^2),每次划分非常不均匀时 |
O(nlogn) | 不稳定 不稳定发生在交换的时刻; |
| 归并排序 | O(nlogn) | —— | O(n) | 稳定 |
因为冒泡和选择排序都是原地排序算法,不需要额外的存储空间。所以其空间复杂度都是O(1)。
归并排序需要额外的空间来存储合并过程中的临时数组,其空间复杂度O(n)。
二分搜索法,是一种【在有序数组中】查找某一特定元素的搜索算法。
有一个背包,最多能承载150斤的重量,现在有7个物品,
重量分别为[35, 30, 60, 50, 40, 10, 25],
价值分别为[10, 40, 30, 50, 35, 40, 30],
应该如何选择才能使得我们的背包背走最多价值的物品?
局部最优解
1、每次都尽量选择当前【价值最高】的物品
重量分别为[35, 30🚗, 60, 50🚗, 40🚗, 10🚗, 25], 130
价值分别为[10, 40②✅, 30, 50①✅, 35④✅, 40③✅, 30], 165
2、每次都尽量选择当前【重量最小】的物品
重量分别为[35④, 30③, 60, 50, 40⑤, 10①, 25②], 140
价值分别为[10✅,40✅, 30, 50, 35✅, 40✅, 30✅], 155
3、每次都尽量选择当前【价值密度最高】的物品
重量分别为[35🚗, 30🚗, 60, 50🚗, 40, 10🚗, 25🚗], 150
价值分别为[10✅, 40✅, 30, 50✅, 35, 40✅, 30✅], 170
价值密度 [0.285⑤, 1.333②, 0.5, 1.0④, 0.875, 4.0①, 1.2③]
想象一下下列场景:
- 从通讯录中寻找某个联系人
- 从一大堆文件中寻找某个文件
- 到了影厅之后,寻找电影票上指定的座位
如果以上情况中,联系人、文件、影厅座位这些“数据”没有按照需要的顺序组织,如何找到想要的特定“数据”呢?会非常麻烦!所以说,对于需要搜索的数据,往往应该先排个序!
前言
1 | // 交换数组中的两个元素 |
算法图解
《034-Data-AlgorithmCollect-iOS》
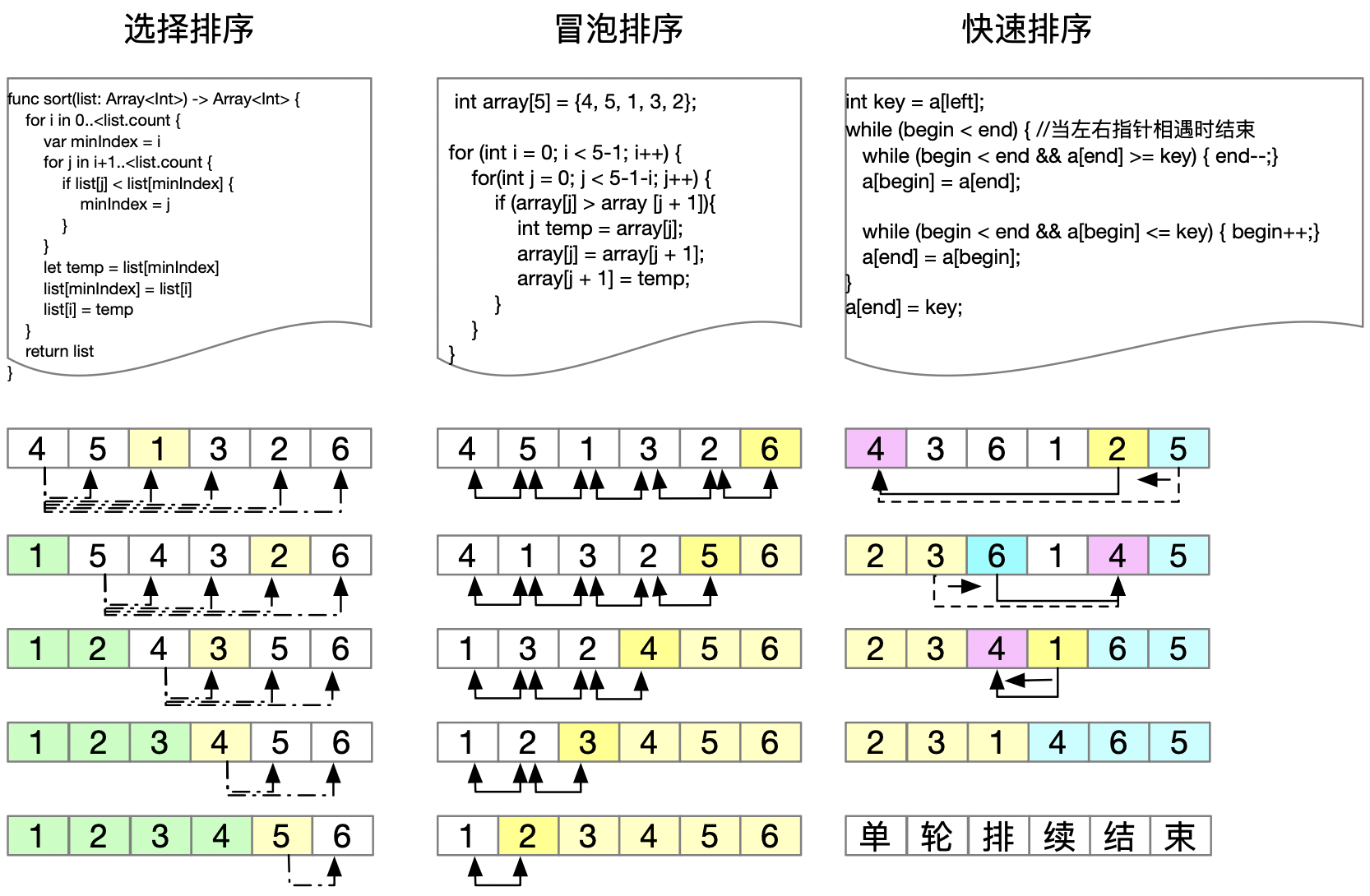
一、冒泡排序
实现一个冒泡排序或者快速排序
从小到大排序:
1 | 假设45132,按从小到大排序 |
二、选择排序
**从数组的第a[i+1]个元素开始到第n个元素,寻找最小的元素(的位置)**。(具体过程为:先设最小位置为i=0,从该位置往后逐一比较,若遇到比之小的则记下该最小值的位置,结束后交换);
先为a[0]取到最小值,再为a[1]取到最小值,再继续…..
从小到大排序:
1 | 假设45132,按从小到大排序 |
三、快速排序
快速排序(Quicksort)是对冒泡排序的一种改进。
同冒泡排序一样,快速排序也属于交换排序,通过元素之间的比较和交换位置来达到排序的目的。
不同的是,冒泡排序在每一轮只把一个元素冒泡到数列的一端,而快速排序在每一轮挑选一个基准元素,并让其他比它大的元素移动到数列一边,比它小的元素移动到数列的另一边,从而把数列拆解成了两个部分。这种思路就叫做分治法。
1 | // 快速排序函数 quickSort(array, 0, [array count] - 1); |
1、排序原理:
设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,

然后将所有比它小的数都放到它左边,所有比它大的数都放到它右边,这个过程称为一趟快速排序。
2、排序流程
快速排序算法通过多次比较和交换来实现排序,其排序流程如下:
(1)首先设定一个分界值,通过该分界值将数组分成左右两部分。
(2)将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值。
(3)然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
(4)重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
四、归并排序
1、划分阶段:通过递归不断地将数组从中点处分开(以把序列分成元素尽可能相等的两半),将长数组的排序问题转换为短数组的排序问题。当子数组长度为 1 时终止划分,开始合并。
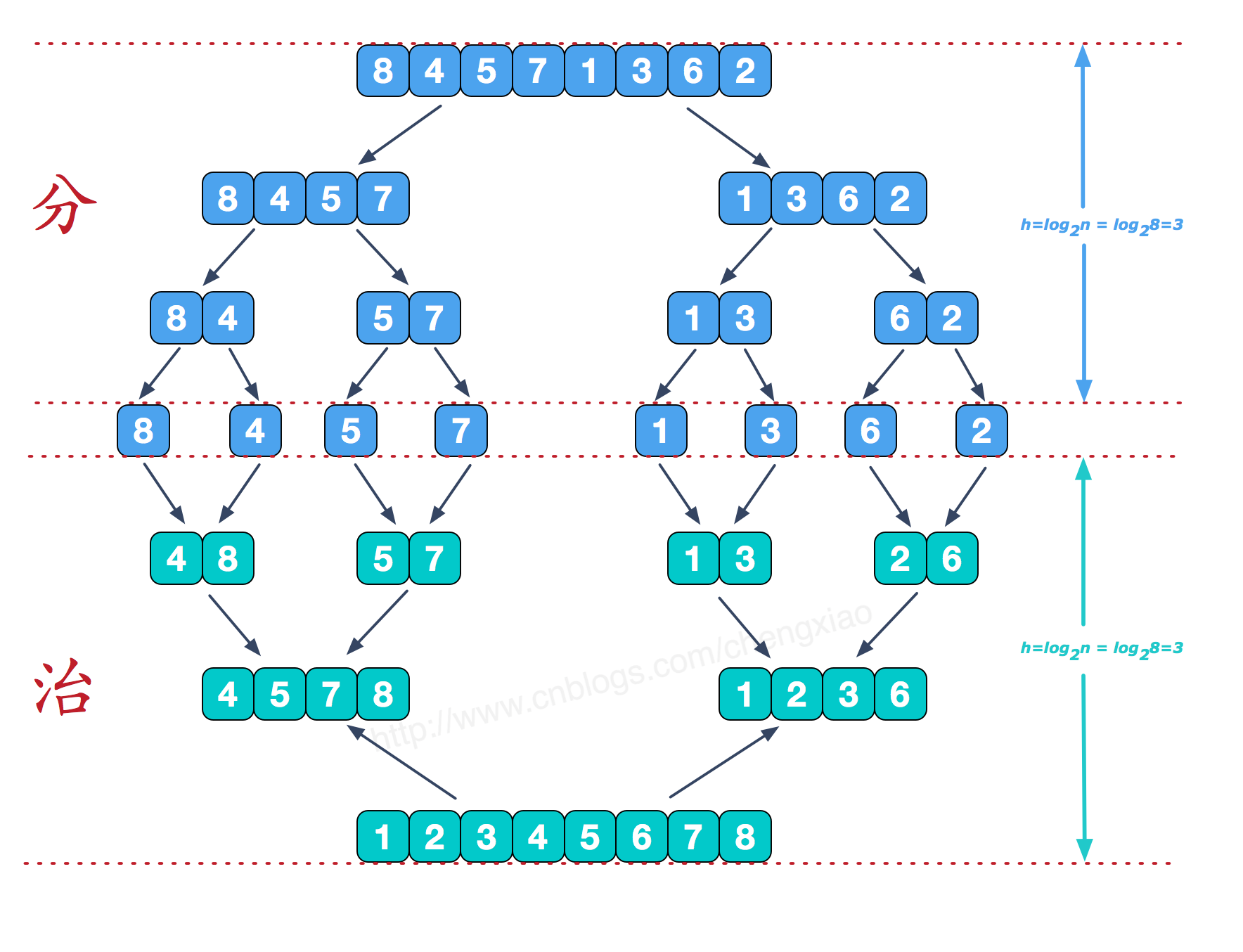
归并排序思路简单,速度仅次于快速排序,为稳定排序算法,一般用于对总体无序,但是各子项相对有序的数列。
2、合并阶段:持续地将左右两个较短的有序数组合并为一个较长的有序数组,直至结束。
归并排序的合并过程如下:
- 初始化:创建两个指针,分别指向两个已排序数组的起始位置。
- 比较元素:比较两个指针所指向的元素。
- 选择较小元素:将较小的元素放入临时数组,并移动该元素所在数组的指针。
- 重复比较:重复步骤2和3,直到其中一个数组的所有元素都被比较过。
- 复制剩余元素:如果一个数组的所有元素都已经被比较并复制到临时数组中,将另一个数组中剩余的元素直接复制到临时数组的末尾。
- 返回临时数组:临时数组现在是一个合并后的有序数组。
示例:要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤。

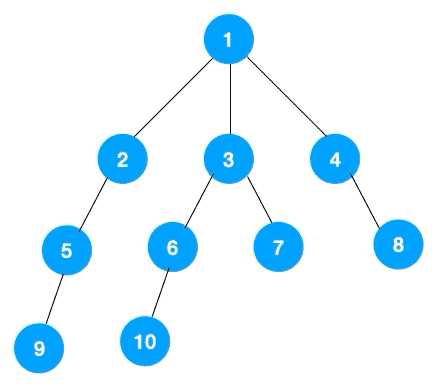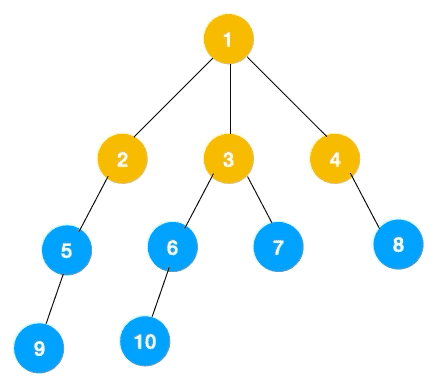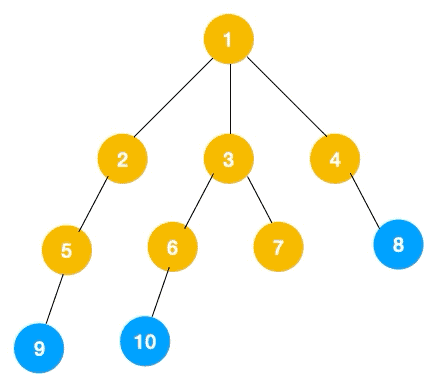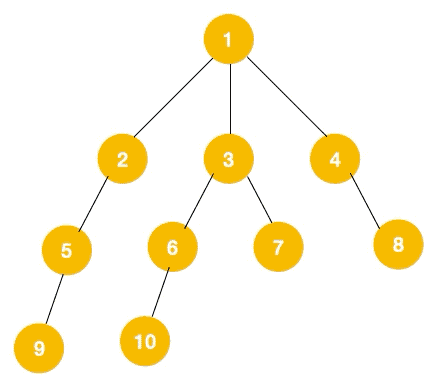
附:深度优先遍历(DFS)和广度优先遍历(BFS)
深度优先遍历(Depth First Search, 简称 DFS)
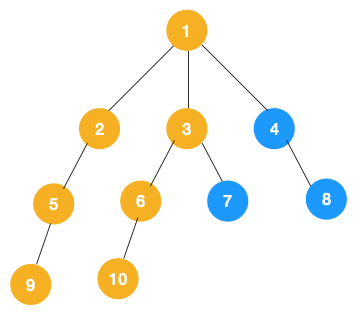
广度优先遍历(Breath First Search, 简称 BFS) 也叫层序遍历,指的是从图的一个未遍历的节点出发,先遍历这个节点的相邻节点,再依次遍历每个相邻节点的相邻节点。
BFS 一般是解决最短路径问题。
iOS算法篇-leetcode题目记录
附:排序算法代码
1、冒泡排序代码实现
1 | - (void)methodMaopao { |
2、选择排序代码实现
1 | func sort(items: Array<Int>) -> Array<Int> { |
3、快速排序代码实现
1 | //单趟 快速排序挖坑法 |
END
< 返回目录